k8s学习笔记
最近再看《Kubernetes in Action》这本书,本文作为学习记录,方便以后回忆。
minikube
win上学习和使用k8s可以安装minikube,这是一个专门用来开发学习k8s的工具。
安装方法在这里
# 启动minikube(win上面需要先启动docker desktop)
minikube startkubectl
kubectl 是k8s的管理工具
# 获取集群信息
kubectl cluster-info
# 获取集群节点列表
kubectl get nodes
# 详细描述节点信息
kubectl describe node 节点名
# 获取pod列表
kubectl get pods缩写:大多数资源可以缩写,如replicationcontroller->rc,pods->po,service->svc、namespace->ns、ReplicaSet->rs等。
kubectl get svc
kubectl get rcminikube不支持LoadBalancer服务,可以使用minikube service 服务名来获取对应的访问地址和端口
ReplicationController用来控制运行单元pod的增加与销毁
# 设置pod运行数量为3
kubectl scale rc rc名 --replicas=3
# 添加-o wide可以显示出pod的内部ip以及所运行在的节点
kubectl get po -o wide
# 可以使用describe获取详细信息
kubectl describe po pod名k8s存在一个图形化工具kubernetes dashboard
minikube中使用minikube dashboard来打开。
pod
pod是容器的一个包裹层,pod中可以存在多个容器,但是大部分时候都是一个容器。
所有pod内的容器间存在一个平坦网络,相当于在一个内网中。
pod可以通过命令直接创建,但是大部分时候都是通过yml(推荐)或者json的形式进行创建。
# 可以以yml的形式来描述pod
kubectl get po pod名称 -o yaml
# 也可以以json的形式来描述pod
kubectl get po pod名称 -o json通过yaml形式创建pod
一个简单的yaml文件如下所示
# 遵循v1版本的k8s api
apiVersion: v1
# 在描述一个pod
kind: Pod
# 元信息
metadata:
# pod名称
name: kubia-manual
spec:
# 里面有几个容器
containers:
- name: kubia-manual
# 容器所用的镜像
image: hopcats/kubia
# 对容器进行资源限制(可以不要)
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
# 应用监听的端口
- containerPort: 8080
protocol: TCP可以使用explain命令来发现更多的api
# 展示顶级结构可使用的标签
kubectl explain pods
# 展示pod.spec下可使用的标签
kubectl explain pod.spec使用create命令从yaml创建pod
kubectl create -f yaml文件名可以使用delete来删除pod:
# 根据名称删除pod,可以指定多个名称,用空格间隔
kubectl delete po pod名称1 pod名称2
# 根据标签删除pod,可以使用=、!=、in、notin等方式
kubectl delete po -l creation_method=manual
# 删除当前名称空间下的所有Pod
kubectl delete po --all如果仅仅删除pod,会使ReplicationController重新创建pod,因此如果刷要完全不需要某一类型的pod时,需要将rc也删除
# 删除当前命名空间下的所有资源(注意同样会删除kubernetes服务,但是该服务应该会在几分钟后重建)
kubectl delete all --all日志
pod运行时允许查看应用日志,如果pod内有多个容器则必须通过-c来指定容器名称:
# 使用logs查看日志
kubectl logs pod名称
# 查看pod内某一个容器的名称
kubectl logs pod名称 -c 容器名称端口转发
除了使用service来访问pod种的应用,还可以使用端口转发来访问:
kubectl port-forward pod名称 外部端口:内部端口标签
yaml中可以使用labels来添加标签:
metadata:
name: kubia-manual-v2
labels:
# 添加两个标签,键值都是自定义的
createion_method: manual
env: prod可以添加参数使展示pod列表时显示标签属性:
# 显示pod列表并展示标签属性
kubectl get po --show-labels
# 显示pod列表并添加特定标签列
kubectl get po -L 标签名1,标签名2
# 列出具有特定标签的pod
kubectl get po -l 标签名
# 列出具有特定标签值的pod(可以写多个标签值,用,拼接)
kubectl get po -l 标签名=标签值
# 列出没有特定标签名的pod
kubectl get po -l "!标签名"
# 为pod添加新标签
kubectl label po pod名称 标签名=标签值
# 修改pod已存在的标签(添加--overwrite参数)
kubectl label po pod名称 标签名=标签值 --overwrite
# 删除pod的某个标签
kubectl label po pod名称 标签名-同时还可以使用in notin来根据标签过滤资源:
# 根据标签在某个值域内来过滤资源
kubectl get po -l "标签名 in (标签值1,标签值2)"
# 根据标签不在某个值域内来过滤资源
kubectl get po -l "标签名 notin (标签值1,标签值2)"node节点同样可以添加标签,并结合yaml来约束pod调度
kubectl label node node名称 标签名=标签值然后在yml中约束pod调度到特定node
spec:
nodeSelector:
# 节点选择器要求将pod部署到具有特定标签值的node上
标签名: "标签值"
# 里面有几个容器
containers:
- name: kubia-manual
# 容器所用的镜像
image: hopcats/kubia注解
通过yaml格式描述pod时可以看到pod的注解(其实叫注释更合适)
使用describe也可以查看注解。
可以使用annotate来添加注解:
# 给pod添加注解(注解前缀有格式要求,如MyName、my.name、123-abc等)
kubectl annotate pod pod名称 注解前缀=注解内容命名空间
不同命名空间下可以有相同名称的资源
# 获取命名空间列表
kubectl get ns默认的get是获取default命名空间下的资源,可以添加--namespace来指定命名空间
# 获取指定命名空间下的pod列表
kubectl get po --namespace 命名空间名称
# 缩写
kubectl get po -n 命名空间名称命名空间也是一种资源,可以通过yaml来创建:
apiVersion: v1
kind: Namespace
metadata:
name: custom-namespace但是这样较为麻烦,可以直接使用命令创建namespace
kubectl create ns custom-namespace创建完之后也可以使用delete进行删除:
kubectl delete ns custom-namespace创建资源时可以使用-n来指定名称空间:
kubectl create -f 文件名.yml -n 名称空间名存活探针
k8s可以自动修复部署的应用,包括检测程序内部的健康。
这是一个通过http接口来检测应用状态的yml:
用来检测的接口不应该有认证,否则会导致一直重启
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
labels:
name: kubia-liveness
spec:
containers:
- name: kubia-liveness
# 一个请求5次就回坏掉的应用(即前五次正常返回2xx或3xx,然后返回5xx)
image: luksa/kubia-unhealthy
resources:
limits:
memory: "128Mi"
cpu: "500m"
# 一个http存活探针
livenessProbe:
httpGet:
path: /
port: 8080可以添加--previous来查看前一个容器的日志
kubectl logs pod名称 --previous也可以使用describe来查看容器为什么重启,重启了多少次
bekuctl describe po pod名称 同时还可以在describe中查看探针的信息,可以看到delay(延迟)、timeout(超时)、period(周期)、failure(失败次数)等信息。
# 一个http存活探针
livenessProbe:
httpGet:
path: /
port: 8080
# 15秒之后再开始探测
initialDelaySeconds: 15大多数时候需要设置一个初始延迟来让程序准备好接受请求
退出信号代表128+x如137代表128+9(SIGKILL),143代表128+15(SIGTERM)
如果是java应用推荐使用httpGet方式的存活探针,而不是启动全心jvm来获取应用信息的Exec探针
ReplicationController
ReplicationController也是一种资源(简称rc),用以确保pod的运行状态。
其中主要包含三个部分:label selector(标签选择器)、replica count(副本个数)、pod template(pod模板)
这里是一个例子:
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
# 副本个数
replicas: 3
# pod选择器决定了rc的操作对象
# selector:
# app: kubia
# 创建新pod所用的模板
template:
metadata:
name: kubia
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080也可以不指定rc种的标签选择器,它会自动根据模板种的标签进行配置。
rc与pod之间平没有直接的关系,而是通过标签选择器产生关联,如果要修改pod的作用域,只需修改其标签。
修改rc可以直接使用scale关键字,也可以使用edit命令:
该命令会使用默认编辑器打开配置文件,保存后会自动生效。
# 编辑rc文件配置
kubectl edit rc rc名称删除rc可以使用delete命令,默认删除时pod也会被删除,如果想要保留pod可以添加--cascade=false参数
--cascade=false参数已废弃
# 删除rc时保留pod(废弃)
kubectl delete rc kubia --cascade=false
# 删除rc时保留pod,并且这些pod会被标记为孤儿
kubectl delete rc kubia --cascade=orphanReplicaSet
ReplicaSet是ReplicationController的作用类似,将会逐渐取代ReplicationController。
可以更好的根据标签去管理pod,一般不会直接创建,而是随着Deployment自动创建。
这是一个通过文件创建的例子:
# 注意apiVersion的值,之前都是直接v1
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
selector:
# 使用了matchLabels,与rc的标签选择器类似
matchLabels:
app: kubia
# template块与rc相同
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubiars有更强大的标签选择器,下例是使用matchExpressions:
selector:
matchExpressions:
# key是必须的
- key: app
# 可选值有In、NotIn、Exists、DoesNotExists
operator: in
values:
- kubiaDaemonSet
DaemonSet会在每个匹配的节点上运行,并且没有副本数的概念,被设计用来运行系统服务。
apiVersion: apps/v1beta2
kind: DaemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- name: main
image: luksa/ssd-monitorJob
Job是用来创建临时任务的资源
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
spec:
# 重启策略不能使用Always,只能选择OnFailure或者Never
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job使用get job查看job
kubectl get job可以使用completion和parallelism两个参数来在同一个job中创建多个Pod
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
# 次作业将完成5次
completions: 5
# 同时可以有几个作业执行
parallelism: 2
# job标记为失败之前重试的次数,默认为6
backoffLimit: 6
template:
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-jobCronJob
CronJob是用来创建定时任务的资源。
apiVersion: batch/v1
kind: CronJob
metadata:
name: batch-job-every-fifteen-minutes
spec:
# 每天每小时的0分、15分、30分、45分时运行
schedule: "0,15,30,45 * * * *"
# pod必须在指定时间后15秒开始运行,否则会标记为Failed
startingDeadlineSeconds: 15
# job用到的资源
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-jobService
pod虽然是运行的基本单元,但是pod是会来回变的,包括名称、ip等信息都是根据情况会不断变化,Service则是提供一个统一的访问方式,而不是单独去指定某一个pod。
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
# 具有app=kubia的pod都属于该服务
selector:
app: kubia
ports:
# 服务可用的端口
- port: 8080
# 将转发到pod的端口
targetPort: 8080在运行的容器中远程执行命令:
# 在一个名为kubia-447dr的pod中执行一个curl命令去访问刚刚创建的service
# 其中 -- 代表kubectl命令项的结束
kubectl exec kubia-447dr -- curl -s http://10.96.48.8:8080service默认随机选择一个Pod提供服务,如果希望特定客户端访问的请求都指向同一个pod只需进行如下设置:
注意:pod重建后可能会造成无法访问service
...
spec:
# 设置sessionAffinity为ClientIP(默认为None)
sessionAffinity: ClientIP
...不基于cookie是因为k8s使用的是tcp/udp进行通信,而不是http,cookie是http协议的一部分
一个service也可以指定多个端口,指定多个端口时每个端口都需要一个名字:
...
ports:
- name: http
port: 8080
targetPort: 8080
- name: https
port: 8443
targetPort: 8443构建pod时也可以给端口命名,然后在service中targetPort也使用名称,这样做的好处是修改pod的端口无需修改service。
如果先创建service,后创建的pod,可以在pod容器中的环境变量获取service的ip和端口:
# 进入容器
kubectl exec kubia-stgxn -it -- bash
env可以通过服务名_SERVICE_PORT和服务名_SERVICE_HOST获取到端口和IP,但是如果service删除重建了pod内部的环境变量并不会改变,因此更好的方式是通过dns来获取。
# 在pod中通过域名访问service
curl http://kubia.default.svc.cluster.local:8080上例中kubia是service名称,default是命名空间svc.cluster.local是在所有集群本地服务名称中使用的可配置集群域后缀。
endpoints
service本身并没有和pod直接关联,而是通过endpoints进行关联,endpoints也是一种资源,它暴露了一个服务的端口和地址的列表。
如果一个service没有选择器,那么将不会自动创建endpoints,可以手动创建。
例子:
一个没有选择器的service:
apiVersion: v1
kind: Service
metadata:
# 名称必须和endpoints匹配
name: external-service
spec:
ports:
- port: 80给对应service创建一个车endpoints:
apiVersion: v1
kind: Endpoints
metadata:
# 名称必须和service匹配
name: external-service
subsets:
- addresses:
- ip: 10.244.0.81
- ip: 10.244.0.82
ports:
- port: 8080即使是这样方式创建的endpoints,在service删除时也会将endpoints删除。
这种方式可以将外部ip的服务连接至svrvice中。
外部服务别名
除了手动修改endpoints这种方式添加外部服务,还可以使用域名添加:
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
# 类型为ExternalName
type: ExternalName
# 实际服务的完全限定域名
externalName: someapi.somecompany.com
ports:
- port: 80这样k8s中的pod就可以像使用本地服务那样使用这个外部服务
服务暴露
服务暴露有三种方式:NodePort、LoadBalance、Ingress。
spec.type 决定了 Service 的暴露方式。 默认为 ClusterIP。 有效选项为 ExternalName、ClusterIP、NodePort 和 LoadBalancer。 “ExternalName”映射到指定的 externalName。 “ClusterIP”分配一个集群内部 IP 地址用于端点的负载平衡。 端点由选择器确定,或者如果未指定,则由手动构建 Endpoints 对象确定。 如果 clusterIP 为“None”,则不会分配任何虚拟 IP,并且端点将发布为一组端点而不是稳定的 IP。 “NodePort”建立在 ClusterIP 之上,并在路由到 clusterIP 的每个节点上分配一个端口。 “LoadBalancer”建立在 NodePort 之上并创建一个外部负载均衡器(如果当前云支持)路由到 clusterIP。 更多信息:
NodePort
NodePort建立在ClusterIP纸上,在每个节点分配一个端口。
顾名思义就是节点端口,在所有节点上开一个相同的端口,然后转发到对应的pod上。
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
# 类型为NodePort
type: NodePort
selector:
app: kubia
ports:
# 集群中的端口
- port: 8080
# 目标pod的端口
targetPort: 8080
# 节点的外部端口
nodePort: 30123LoadBalancer
LoadBalancer在NodePort基础上在外部建立一个均衡器。
LoadBalancer是负载均衡器,有独立的ip,并且会将数据重定向到pod中,minikube实际并不支持,但是仍然可以创建。
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
selector:
app: kubia
ports:
- port: 8080
targetPort: 8080Ingress
每个LoadBalancer都有自己的负载均衡器,并且需要独立IP,而Ingress可以根据请求信息暴露多个服务(因为Ingress基于http)。
minikube中有一个插件可以试用Ingress,使用minikube addons list查看ingress组件是否启用,如未启用通过minikube addons enable ingress启用插件,启用之后可以通过kubectl get po --all-namespaces看到组件也建立了Pod在运行。
# 书中的并不一样
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kubia
spec:
rules:
# 访问的域名,ingress会根据域名转发
- host: test.psgame.fun
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: kubia-nodeport
port:
number: 8080接着访问域名就可以访问到具体应用。
其中rules和paths字段都是数组,也就是可以根据域名和路径暴露不同的service。
如果是minikube中,还需要启用ingress-dns插件minikube addons enable ingress-dns,创建好Ingress之后开启minikube的转发:minikube tunnel(保持控制台开启),然后修改host文件把ingress中的域名修改为本地地址127.0.0.1 自定义域名(或者直接用我的域名test.psgame.fun,解析到了127.0.0.1上)
Ingress并不会把请求转发到服务上,而是根据和服务相关的endpoints直接访问pod。
Ingress + TLS
也就是使Ingress支持https
使用kubectl create secret tls psgame.fun-tls --key psgame.fun.key --cert psgame.fun_bundle.crt创建一个secret资源,这里我使用了自己的证书。
然后修改ingress创建文件:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kubia
spec:
tls:
- hosts:
- www.psgame.fun
secretName: psgame.fun-tls
rules:
- host: www.psgame.fun
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: kubia-nodeport
port:
number: 8080再次访问会自动跳转到https
服务暴露特点
spec.externalTrafficPolicy 表示此服务是否希望将外部流量路由到节点本地或集群范围的端点。 “Local”保留客户端源 IP 并避免 LoadBalancer 和 Nodeport 类型服务的第二跳,但存在潜在的不平衡流量传播风险。 “Cluster”模糊了客户端源 IP,可能会导致到另一个节点的第二跳,但应该具有良好的整体负载分布。
LoadBalancer的转发会导致不必要的网络跳数,可以通过设置externalTrafficPolicy来减少不必要的转发,但是设置为local之后可能会导致负载不均衡了。
# NodePort服务的yml
spec:
externalTrafficPolicy: Local就绪探针
容器并非一启动就可以提供服务,一般都需要启动时间,就绪探针就是用来检测应用是否成功启动。
和存活探针一样,也有三种类型:
- Exec探针,执行进程的地方,容器的状态由进程的退出状态码决定。
- HTTP GET 探针,向容器发送http请求,通过状态码判断是否准备好
- TCP 探针,打开一个TCP连接到指定端口,如果连接建立,就认为容器已就绪。
这是一个exec存活探针的例子:
apiVersion: v1
kind: ReplicationController
...
spec:
...
template:
...
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- containerPort: 8080
readinessProbe:
exec:
# 如果ready文件存在代表已就绪
command:
- "ls"
- "/var/ready"磁盘挂载
emptyDir
volumes:
- name: html
emptyDir: { }emptyDir就是一个空文件夹的临时目录,生命周期和pod是一样的,如果pod被删除,那么emptyDir也会被删除。
并且emptyDir是不能主动指定在宿主机上面的位置的。
emptyDir还可以指定介质,将medium参数设置为Memory可以将介质值定在内存上。
gitRepo
gitRepo是建立在emptyDir上的,基本和emptyDir一致。在pod创建时会从制定仓库拉取文件(但是远程仓库更新之后本地的文件并不会变),因此如果git仓库有变更,则需要吧pod删除重新创建一遍。
volumes:
- name: html
gitRepo:
# 仓库
repository: https://github.com/luksa/kubia-website-example.git
# 分支
revision: master
# 拉取到根目录(不指定时将会克隆到项目同名文件夹中)
directory: .hostPath
hostPath就是宿主机路径映射,类似docker挂在的目录。
hostPath通常用于访问node上的(也就是宿主机)数据,而不是用来存储持久化数据。(因为k8s是分布式的,存储在一个节点上之后如果pod被分配到其他节点,那么这些数据将访问不到,因此单节点时也可以用来存储持久化数据。)
持久化存储
NFS
如果k8s运行在Google Kubernetes Engine(GCE)中,那么存储可以使用gcePersistentDisk,如果是amazon的AWS EC2上则可以使用awsElasticBlockStore如果是微软的Azure则可以使用azureFile或者azureDisk。不同的k8s引擎服务商都会提供对应的存储服务。
如果是运行在自建的服务器上,可以使用NFS(Network File System),只需要挂载一个nfs的共享:
volumes:
- name: mongodb-data
mfs:
server: 1.2.3.4
path: /some/path但是这样会将存储和pod耦合在一起。并且开发人员需要了解实际所部署的服务器环境,使用持久卷可以解决这个问题。
Persistent Volume(PV)
由集群管理员在k8s中创建持久卷并注册,开发人员只需要生命卷,k8s会自动寻找可匹配的持久卷。
具体过程如下:

minikube 使用hostPath
apiVersion: v1
kind: PersistentVolume
metadata:
name: mongodb-pv
spec:
capacity:
# 定义大小
storage: 1Gi
accessModes:
# 可以被单个节点挂载为读写模式
- ReadWriteOnce
# 可以被多个节点挂载为只读模式
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /D/Share/Temp/mongodb持久卷声明:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
resources:
requests:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: ""创建好声明之后,k8s会找到合适的持久卷并绑定到声明,大小还有权限都要符合。
一般来说,PV由运维人员创建,是对实际存储的抽象。PVC由开发人员创建,Pod中对存储需求的抽象。
动态配置 Storage Class
pv仍然需要管理员来创建,想取消这一部可以通过Storage Class动态创建存储资源(缩写sc)。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
# minikube使用的卷插件,不同k8s厂商会有对应的插件
provisioner: k8s.io/minikube-hostpath
parameters:
type: pd-ssd一个使用storage class创建的例子。
pvc使用例子如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc
spec:
# 通过名称进行使用
storageClassName: fast
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnceStorageClasses的好处在于,声明是通过名称引用它们的。因此,只要StorageClass名称在所有这些名称中相同,PVC定义便可跨不同集群移植。
不指定名称的动态配置
最终最简单的方式就是不指定storage class名称,只需创建pvc:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongodb-pvc2
spec:
resources:
requests:
storage: 100Mi
accessModes:
- ReadWriteOnceConfigMap和Secret
ConfigMap
创建
configmap可以被pod直接通过环境变量使用,不同的名称空间可以有不同的configmap。
通过命令行创建configmap:
# 创建了一个名为fortune-config的configmap,里面包含一跳sleep-interval=25的映射
# 可以在后面跟上多个--from-literal来添加多个配置
kubectl create configmap fortune-config --from-literal=sleep-interval=25yaml格式创建ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: fortune-config
data:
sleep-interval: "25"创建configmap时还可以根据现在conf配置文件创建:
# 根据文件创建
kubectl create configmap my-config --from-file=config-file.conf
# 还可以将文件的内容存在某一个键下
kubectl create configmap my-config --from-file=customKey=config-file.conf
# 引入目录下所有文件,这样会为每个文件创建单独条目(仅限文件名可以作为合法键值的文件)
kubectl create configmap my-config --from-file=/path/to/dir上例中的集中方式可以同时使用:
kubectl create cm my-config
--from-file=foo.json
--from-file=bar=foobar.conf
--from-file=config-opts/
--from-literal=some=thing创建出来的configmap如下所示:

应用到pod
apiVersion: v1
kind: Pod
metadata:
name: fortune-env-from-configmap
spec:
containers:
- name: fortune-env-from-configmap
image: luksa/fortune:env
env:
# 设置环境变量INTERVAL
- name: INTERVAL
valueFrom:
# 使用configmap
configMapKeyRef:
# configmap的名称
name: fortune-config
# 环境变量被为设置为该键对应的值
key: sleep-interval
# 在参数中引用环境变量
args: ["$(INTERVAL)"]如果引用的configmap不存在,那么pod会启动失败。后续如果创建了对应名称的configmap,失败的pod会自动启动。
也可以将configmap的引用设置为可选:configMapKeyRef.optional: true这样即使configmap不存在,pod也会启动成功。
将configmap所有条目作为环境变量
spec:
containers:
- image: some-image
# 使用envFrom来设置configmap中的所有条目
envFrom:
# 添加一个前缀,configmap中的键会自动添加上该前缀;如果不设置前缀,那么就是configmap中的键
- prefix: CONFIG_
configMapRef:
# 使用的configmap名称
name: my-config-map如果configmap中有不符合环境变量名称规则的键(如MY-CONFIG这种有-的),k8s会忽略该变量,并且没有通知。
将configmap中的条目暴露为文件
有时候configmap中的值是配置文件的形式,比如nginx配置文件或者是项目配置文件,这个时候可以创建configmap卷,将其在Pod内映射为文件,方便使用。
apiVersion: v1
kind: Pod
metadata:
name: fortune-configmap-volume
spec:
containers:
- image: nginx:alpine
name: web-server
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html
readOnly: true
# 挂载位置
- name: config
# 挂载文件夹会使原本的文件被隐藏
mountPath: /etc/nginx/conf.d
readOnly: true
- name: config
mountPath: /tmp/whole-fortune-config-volume
readOnly: true
ports:
- containerPort: 80
name: http
protocol: TCP
resources:
limits:
memory: "128Mi"
cpu: "500m"
volumes:
- name: html
emptyDir: {}
# 卷使用的是configmap类型
- name: config
configMap:
name: fortune-config
# 可以设置文件权限
defaultMode: "6600"
items:
# 可以指定挂载的键
- key: my-nginx-config.conf
# 以及映射的文件名
path: gzip.conf映射为文件时,如果挂载成一个文件夹,会使文件夹原本的文件隐藏,通过subPath可以仅挂载一个文件,不影响原本的文件:
spec:
containers:
- image: some/image
volumeMounts:
- name: myvolume
# 挂载路径到文件而不是文件夹
mountPath: /etc/someconfig.conf
# 仅挂载指定条目,而不是完整的卷
subPath: myconfig.confSecret
Secret是专门用来保存敏感数据的,比如证书和私钥,和configmap类似,也是键值对的形式,但是之后保存在内存中,不会保存在物理存储上。
每个Pod都会被挂载上一个默认的secret卷,其中包含了内部安全访问所需要的信息,可以通过配置禁止这个默认挂载。
创建:
kubectl create secret generic fortune-https --from-file=https.key --from-file=https.cert通过kebectl get secret fortune-https -o yaml查看secret时可以发现数据是以base64的形式保存的,secret大小限制1M。
secret使用与configmap基本一致,可以挂载到pod中,也可以暴露为环境变量。
应用访问Pod元数据
应用可以通过环境变量访问pod的信息,但是只能访问预先知道的,在运行时才能知道的信息(比如Pod的IP、主机等)可以通过Downward API来获取。
通过环境变量暴露元数据
pod的yml定义中,环境变量可以引用元数据:
apiVersion: v1
kind: Pod
metadata:
name: downward
spec:
containers:
- name: main
image: busybox
command: ["sleep", "9999999"]
resources:
requests:
cpu: 15m
memory: 100Ki
limits:
# 100m代表千分之100,1就代表整颗CPU的运算能力
cpu: 100m
memory: 4Mi
env:
- name: POD_NAME
valueFrom:
fieldRef:
# 引用元数据的名称
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: SERVICE_ACCOUNT
valueFrom:
fieldRef:
fieldPath: spec.serviceAccountName
- name: CONTAINER_CPU_REQUEST_MILLICORES
valueFrom:
resourceFieldRef:
resource: requests.cpu
divisor: 1m
- name: CONTAINER_MEMORY_LIMIT_KIBIBYTES
valueFrom:
resourceFieldRef:
# 上面实际内存定义的是4Mi,基数是1Ki,那么变量的值就是4096;CPU同理
resource: limits.memory
divisor: 1Ki通过卷暴露元数据
如果不想通过环境变量的方式来暴露元数据,也可以通过卷挂载的方式来暴露:
apiVersion: v1
kind: Pod
metadata:
name: downward
labels:
foo: bar
annotations:
key1: value1
key2: |
multi
line
value
spec:
containers:
- name: main
image: busybox
command: ["sleep", "9999999"]
resources:
requests:
cpu: 15m
memory: 100Ki
limits:
cpu: 100m
memory: 4Mi
volumeMounts:
# 把变量都挂载到这个目录
- name: downward
mountPath: /etc/downward
volumes:
- name: downward
downwardAPI:
items:
# path其实相当于文件名
- path: "podName"
fieldRef:
fieldPath: metadata.name
- path: "podNamespace"
fieldRef:
fieldPath: metadata.namespace
- path: "labels"
fieldRef:
fieldPath: metadata.labels
- path: "annotations"
fieldRef:
fieldPath: metadata.annotations
- path: "containerCpuRequestMilliCores"
resourceFieldRef:
containerName: main
resource: requests.cpu
divisor: 1m
- path: "containerMemoryLimitBytes"
resourceFieldRef:
containerName: main
resource: limits.memory
divisor: 1通过卷得方式暴露的信息,在修改后会同步到pod内部,但是通过环境变量形式修改的不会。
Kubernetes REST API
本机与API服务器交互
通过kubectl cluster-info可以查看k8s的api地址,但是需要认证。
可以通过kubectl proxy --port=8080来代理认证,然后访问8080端口就可以看到api列表。
Pod内部与服务器交互
Pod创建时在内部有认证文件:

但是通过认证文件手动认证过于复杂,可以通过ambassador简化交互。
不同语言有不同的交互客户端,java可以使用Fabric 8,示例代码如下:
Java 访问k8s API
package kubia;
import io.fabric8.kubernetes.api.model.Pod;
import io.fabric8.kubernetes.api.model.PodList;
import io.fabric8.kubernetes.client.DefaultKubernetesClient;
import io.fabric8.kubernetes.client.KubernetesClient;
import java.util.Arrays;
public class Fabric8ClientTest {
public static void main(String[] args) throws Exception {
KubernetesClient client = new DefaultKubernetesClient();
// list pods in the default namespace
PodList pods = client.pods().inNamespace("default").list();
pods.getItems().stream().forEach(s -> System.out.println("Found pod: " + s.getMetadata().getName()));
// create a pod
System.out.println("Creating a pod");
Pod pod = client.pods().inNamespace("default").createNew()
.withNewMetadata()
.withName("my-programmatically-created-pod")
.endMetadata()
.withNewSpec()
.addNewContainer()
.withName("main")
.withImage("busybox")
.withCommand(Arrays.asList("sleep", "99999"))
.endContainer()
.endSpec()
.done();
System.out.println("Created pod: " + pod);
// edit the pod (add a label to it)
client.pods().inNamespace("default").withName("my-programmatically-created-pod").edit()
.editMetadata()
.addToLabels("foo", "bar")
.endMetadata()
.done();
System.out.println("Added label foo=bar to pod");
System.out.println("Waiting 1 minute before deleting pod...");
Thread.sleep(60000);
// delete the pod
client.pods().inNamespace("default").withName("my-programmatically-created-pod").delete();
System.out.println("Deleted the pod");
}
}不同语言也有不同的客户端:
Golang client—https://github.com/kubernetes/client-go
Python—https://github.com/kubernetes-incubator/client-python
Fabric8维护的Java客户端—https://github.com/fabric8io/kubernetes-client
Amdatu维护的Java客户端—https://bitbucket.org/amdatulabs/amdatu-kubernetes
tenxcloud维护的Node.js客户端—https://github.com/tenxcloud/node-kubernetesclient
GoDaddy 维 护 的 Node.js 客 户 端 —https://github.com/godaddy/kubernetes-client
PHP—https://github.com/devstub/kubernetes-api-php-client
另⼀个PHP客户端—https://github.com/maclof/kubernetes-client
Ruby—https://github.com/Ch00k/kubr
另⼀个Ruby客户端—https://github.com/abonas/kubeclient
Clojure—https://github.com/yanatan16/clj-kubernetes-api
Scala—https://github.com/doriordan/skuber
Perl—https://metacpan.org/pod/Net::Kubernetes
Deployment
升级应用
修改rc
如果要升级应用,可以直接修改rc,使其自动删除旧版本pod,并创建新版本pod,这样做比较简单但是会存在一段时间服务不可用。

修改service
通过提前创建新版本的pod,然后修改service也可以切换,这样会占用较多的服务器资源。

Deployment
deployment可以自动管理升级流程,这是一个yml示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kubia
spec:
selector:
matchLabels:
app: kubia
replicas: 3
template:
metadata:
labels:
app: kubia
spec:
containers:
- name: nodejs
image: luksa/kubia:v1
resources:
limits:
memory: "128Mi"
cpu: "500m"升级命令:kubectl set image deploy kubia nodejs=luksa/kubia:v2
deployment会自动创建rs,然后创建pod
deployment缩写deploy
deployment部署之后如果需要升级,只需要修改镜像即可,下面是修改deployment的一些方法:
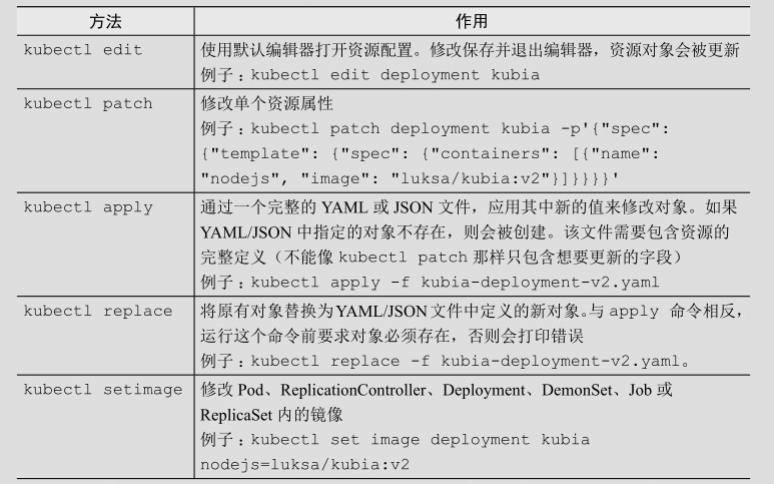
注意:如果Deployment中引用了ConfigMap(或者Secret),那么更改ConfigMap并不会出发升级操作,如果需要触发升级操作,可以通过创建一个新的ConfigMap然后修改模板使其引用新的ConfigMap,然后再更新。
回滚升级
如果新版本发现bug,Deployment也可以很方便的回滚最后一次升级:
kubectl rollout undo deploy kubiadeployment升级后旧版本的rs也不会删除,因此可以很方便的回滚。
并且还可以使用--to-revision=版本号来回滚到特定版本
控制升级速率
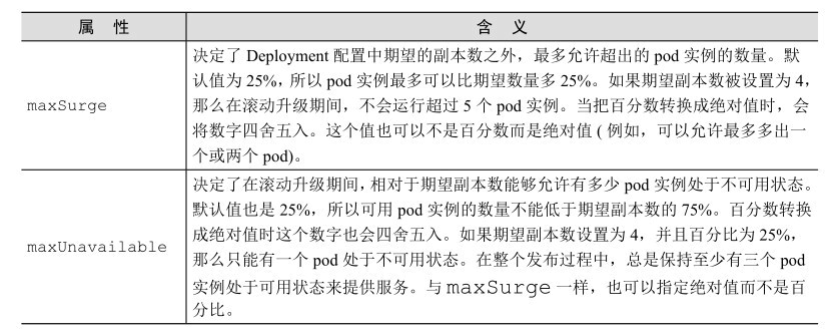
升级时可以通过maxSurge和maxUnavailable来控制升级的速度,配置文件如下所示
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
type: RollingUpdate两个参数的解释如下图所示:
暂停与恢复滚动升级
在修改为高版本镜像之后,立马(几秒之内)暂停升级,会使高版本与低版本同时运行,这样就可以查看高版本的日志,相当于运行了一个金丝雀版本。
# 设置为高版本镜像
kubectl set image deploy kubia nodejs=luksa/kubia:v4
# 暂停升级
kubectl rollout pause deploy kubia
# 恢复滚动升级
kubectl rollout resume deploy kubia金丝雀版本的正确发布方式是使用两个deploy并同时修改他们的数量。
minReadySeconds
minReadySeconds配合探针可以保证在升级期间,镜像内应用完全准备好之后才会接受请求。
deadline
默认情况下,在10分钟内不能完成滚动升级的话,将被视为失败。这个时间可以通过设置spec的progressDeadlineSeconds来指定。
因为升级不再继续,只能使用undo来取消升级:
kubectl rollout undo deploy kubiaStatefulset
rs和rc比较适合管理无状态的pod,管理有状态的应用时一般使用statefulset。statefulset管理的pod会有规律的Pod名称,而不是想rc一样是随机生成的,并且pod被删除之后,重新创建的Pod会有相同的名称和ip。
使用Statefulset创建有状态pod之前,一般会创建一个headless的service(无头service)来提供访问,和普通service的区别就是headless类型的service的spec.clusterIp设置为None,即通过dns访问service,而没有固定ip,并且可以使pod之间可以相互发现。
Statefulset会按顺序创建pod,并且前一个状态变为running之后才会创建下一个。在缩容时也会按照顺序删除,并且删除pod之后会留下存储卷。
访问Statefulset
访问Statefulset创建的pod可以通过另一个Pod,在其中做端口转发,还有一种方式是通过API服务器,
Statefulset发现伙伴节点
节点之间的发现是借助dns完成,类似kubia.default.svc.cluster.local这种形式。
